

Transfer Learning From Speaker Verification

Transfer Learning From Speaker Verification To Multispeaker Text To Speech Synthesis Papers With Code

Transfer Learning From Speaker Verification To Multispeaker Text To Speech Synthesis By Salman Faroz Voice Tech Podcast Medium

Typical Block Diagram Showing Working Of Speech Recognition System Speech Recognition Speech Recognition
The Flow Chart Of Our Speaker Verification System Download Scientific Diagram
Illustration Of The Oral Airflow Based Speaker Verification For The Download Scientific Diagram

Transfer Learning From Speaker Verification To Multispeaker Text To Speech Synthesis By Salman Faroz Voice Tech Podcast Medium

Transfer Learning from Speaker Verification to Multispeaker Text-To-Speech Synthesis NeurIPS 2018 CorentinJReal-Time-Voice-Cloning Clone a voice in 5 seconds to generate arbitrary speech in real-time SPEAKER VERIFICATION SPEECH SYNTHESIS TEXT-TO-SPEECH SYNTHESIS TRANSFER LEARNING.
Transfer learning from speaker verification. Transfer Learning from Speaker Verification to Multispeaker Text-To-Speech Synthesis. Authors do not seem to offer any truly new theoretical. Weiss Quan Wang Jonathan Shen Fei Ren Zhifeng Chen Patrick Nguyen Ruoming Pang Ignacio Lopez Moreno Yonghui Wu Google Inc.
Specifically speaker verification of short utterances can be viewed as a task in the domain with a limited amount of long utterances. 1162021 We demonstrate that the proposed model is able to transfer the knowledge of speaker variability learned by the discriminatively-trained speaker encoder to the new task and is able to synthesize. Therefore transfer learning for PLDA can also be adopted to learn discriminative information from other domains with a great deal of long utterances.
Our system consists of three independently trained components. Transfer Learning from Speaker Verification to Multispeaker Text-To-Speech Synthesis. 5102020 multispeaker speech synthesis.
Transfer Learning for Speaker Verification on Short Utterances Qingyang Hong 1 Lin Li Lihong Wan Jun Zhang1 Feng Tong2 1School of Information Science and Technology Xiamen University China 2Key Lab of Underwater Acoustic Communication and Marine Information Technology of MOE Xiamen University China Corresponding tolilinxmueducn Abstract. We manage to enhance the knowledge transfer from the speaker verification to the speech synthesis by engaging the speaker verification network. Weiss Quan Wang Jonathan Shen Fei Ren Zhifeng Chen Patrick Nguyen Ruoming Pang Ignacio Lopez Moreno.
Transfer Learning from Speaker Verification to Multispeaker Text-To-Speech Synthesis. 912017 PLDA-based speaker verification Fig. Transfer Learning from Speaker Verification to Multispeaker Text-To-Speech SynthesisEdit social preview.
1 a speaker encoder network trained on a speaker verification task using an independent dataset of noisy speech without transcripts from thousands of speakers to generate a fixed-dimensional embedding vector from only seconds of reference speech from a target speaker. NeurIPS 2018 Ye Jia Yu Zhang Ron J. We demonstrate that the proposed model is able to transfer the knowledge of speaker variability learned by the discriminatively-trained speaker encoder to the new task and is able to synthesize natural speech from speakers that were not seen during training.

3 Channel Spectrum Analyzer Circuit Diagrams Schematics Electronic Projects Spectrum Analyzer Circuit Diagram Electronics Projects

Did You Know Smartphone Makers Oneplus Oppo And Vivo Are All Owned By The Same Company Oneplus Vivo One Plus

5 Cara Mengatasi Ppsspp Force Close Di Android Updated Dunia Trik Android Aplikasi

Github Codejin Multi Speaker Tts Implementation Of Multi Speaker Tts

Don T Wait Change Icloud Keychain S Security Code Or Phone Number Now Icloud Coding Phone Numbers

Electronics Free Full Text Speaker Verification Employing Combinations Of Self Attention Mechanisms Html

Pin On Web Pixer

Add Social Login And Sharing To Wordpress Using Miniorange Wordpress Ads Social

Pdf Speaker Recognition
News Android Android43 Google S Rcs Chat Features Now Rolling Out To Phones In The Uk And France Messaging App Fake Contacts Messages

Speaker Verification Papers With Code

Decktopus Lifetime Deal For 49 Buy Software Apps Software Apps Lifetime Presentation
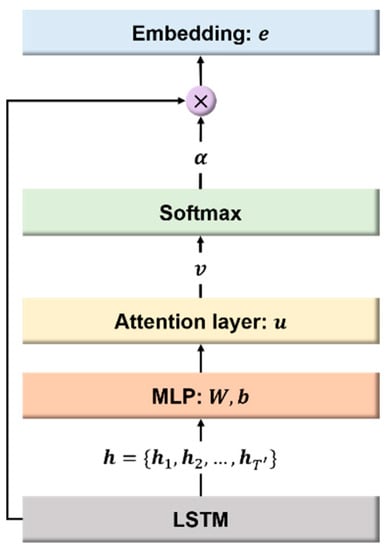
Electronics Free Full Text Speaker Verification Employing Combinations Of Self Attention Mechanisms Html
