

Transfer Learning Learning Rate
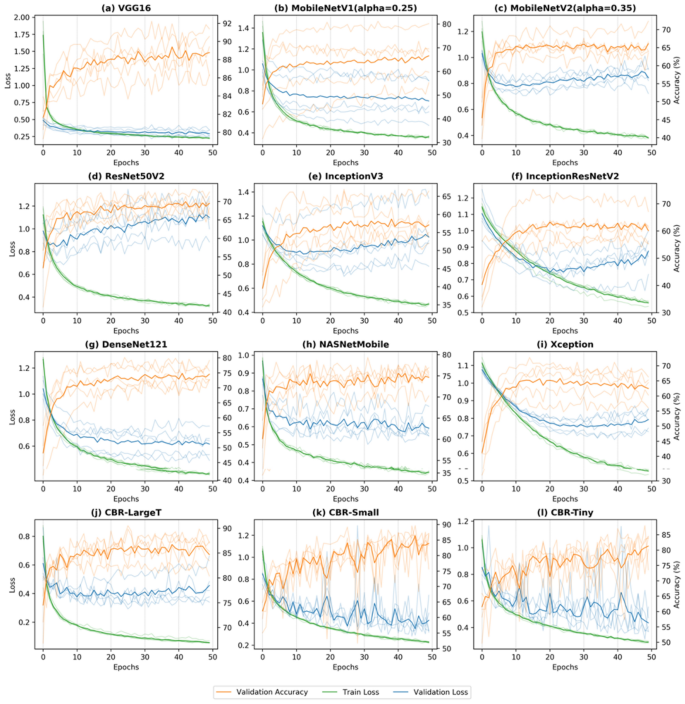
Evaluation Of Transfer Learning In Deep Convolutional Neural Network Models For Cardiac Short Axis Slice Classification Scientific Reports

Transfer Learning Deep Learning For Everyone Data Science Central Deep Learning Machine Learning Book Machine Learning Artificial Intelligence
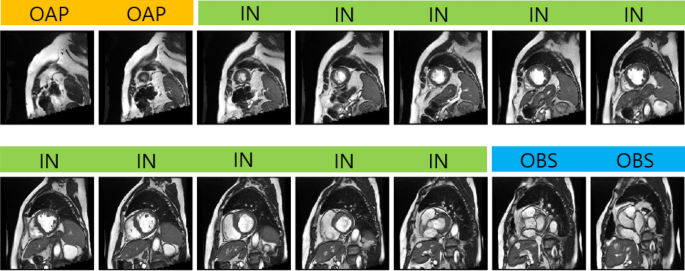
Evaluation Of Transfer Learning In Deep Convolutional Neural Network Models For Cardiac Short Axis Slice Classification Scientific Reports
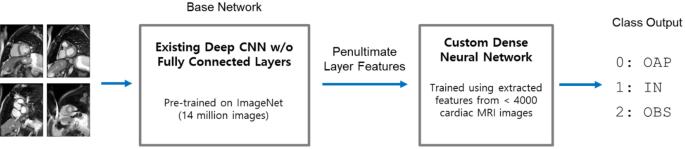
Evaluation Of Transfer Learning In Deep Convolutional Neural Network Models For Cardiac Short Axis Slice Classification Scientific Reports
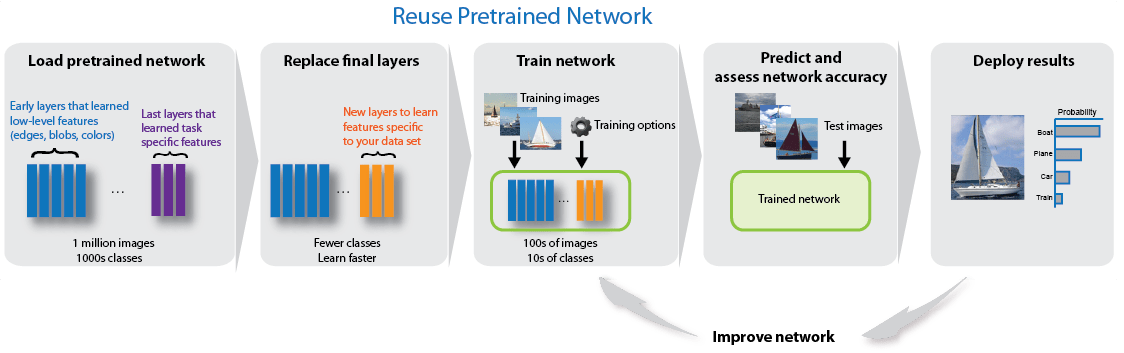
Alexnet Convolutional Neural Network Matlab Alexnet
A Survey On Image Data Augmentation For Deep Learning Springerlink

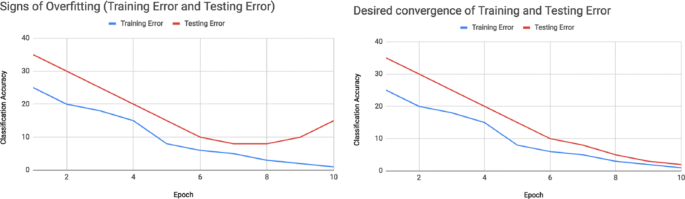
This is in contrast to how people normally configure the learning rate which is to use the same rate throughout the network during training.
Transfer learning learning rate. 652019 The learning rate schedule generates a step function that decays the initial learning rate 01 by a factor of 10 at the 6th and 9th epochs. Transfer learning is an optimization that allows rapid progress or improved performance when modeling the second task. Restore Backbone from disk.
Additionally increasing the learning rate can also allow for more rapid traversal of saddle point plateaus. Transfer learning is the improvement of learning in a new task through the transfer of knowledge from a related task that has already been learned. 11202017 Differential Learning Rates LR is a proposed technique for faster more efficient transfer learning.
Of rate-compatible polar codes and their training data are investigated and the proposed transfer learning-based training method of NNDs for the rate-compatible polar codes is then presented in Section3. 11212017 How lessmore the learning rates for initial and middle layers depends on the data correlation between the pre-trained model and our required model. The L2T Framework A L2T agent previously conducted transfer learning sev-eral times and kept a record of N e transfer learning ex-periences.
In transfer learning a machine exploits the knowledge gained from a previous task to improve generalization about another. Ad Join Millions of Learners From Around The World Already Learning On Udemy. Here through this technique we will monitor the validation accuracy and if it seems to be a plateau in 3 epochs it will reduce the learning rate by 001.
Below its effectiveness is tested along with other LR strategies. 4272020 Transfer learning is a research problem in Deep learning DL that focuses on storing knowledge gained while training one model and applying it to another model. The general idea is to use a lower Learning Rate for the earlier layers and gradually increase it in the latter layers.
This is because the learning rate at that instant is very large comparatively and thus the optimisation isnt able to reach the global optimum. Performance comparison with the conventional separate learning is given in Section4. 1252019 By allowing the learning rate to increase at times we can jump out of sharp minima which would temporarily increase our loss but may ultimately lead to convergence on a more desirable minima.

Transfer Learning With Chest X Rays For Er Patient Classification Scientific Reports
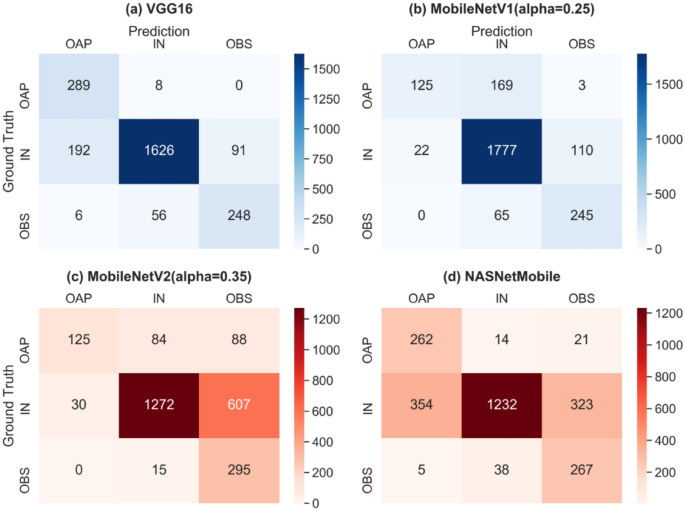
Evaluation Of Transfer Learning In Deep Convolutional Neural Network Models For Cardiac Short Axis Slice Classification Scientific Reports
Https Arxiv Org Pdf 2009 08369

Estimating An Optimal Learning Rate For A Deep Neural Network Learning Deep Learning Optimization
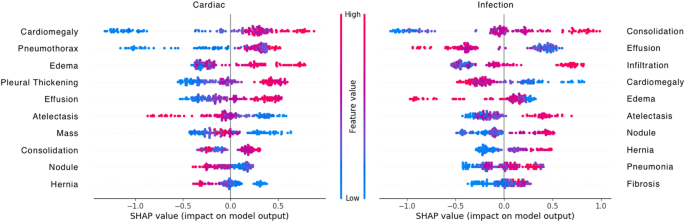
Transfer Learning With Chest X Rays For Er Patient Classification Scientific Reports
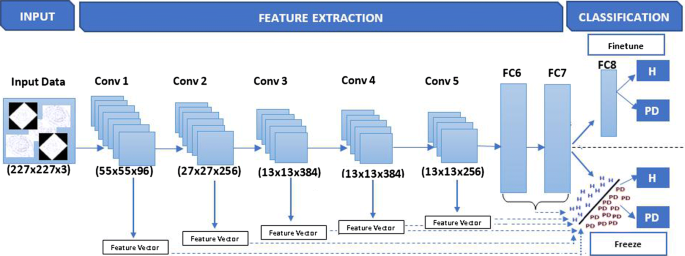
Refining Parkinson S Neurological Disorder Identification Through Deep Transfer Learning Springerlink
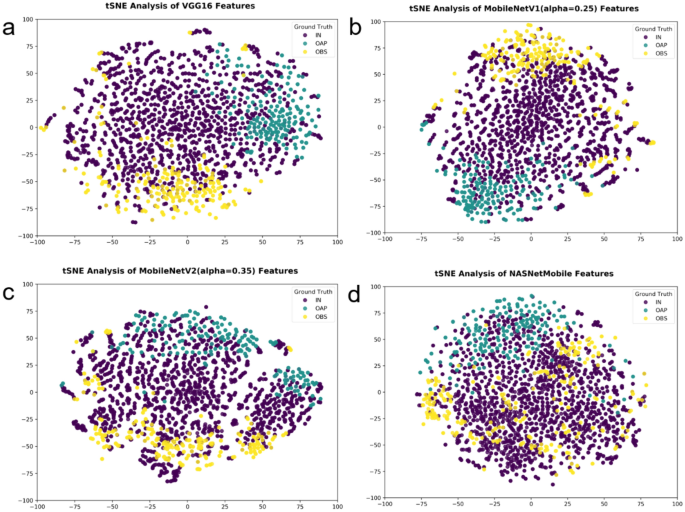
Evaluation Of Transfer Learning In Deep Convolutional Neural Network Models For Cardiac Short Axis Slice Classification Scientific Reports
Https Arxiv Org Pdf 2004 11676
Transfer Learning Using Differential Learning Rates Learning Transfer Rate

The Power Of Transfer Learning With Fastai Crack Detection In Concrete Structure By Muhammad Farooq The Startup Medium

Transfer Learning In 2020 Machine Learning Learning Data Science

Pin By Leong Kwok Hing On Deep Learning Deep Learning Learning Optimization

3 Learning To Ask Good Business Questions Analytical Skills For Ai And Data Science Data Science Business Questions This Or That Questions
